About Me

Hi, my name is Yucai Bai. I’m an algorithm engineer at Noah Ark Computer Vision Lab in HUAWEI, and I still focus on the project and technology of self-driving vehicles. I believe L5-level intelligent vehicles will change our lives one day. Before that, we can do a lot.
Education
Sichuan University ( 2017.9 - 2020.8 )
Tiansi Lab, College of Computer Science
Master of Engineering, received in 2020.8
Major in Software Engineering
Supervised under Prof. Yi-Fei Pu
GPA: 3.20 / 4.0
Research Interests
- Reconstruction
- Transfer Learning and Multi-Task Learning
- Extreme Low-Resolution Action Recognition
Publications
- Yucai Bai, Qin Zou, et al. Extremely Low Resolution Action Recognition with Confident Spatial-Temporal Attention Transfer, accepted by IJCV. [PDF]
- Yucai Bai, Lei Fan, et al. Monocular Outdoor Semantic Mapping with a Multi-task Network, accepted by IROS2019 [PDF][VIDEO][CODE]
- Yucai Bai, Sen Zhang, Miao Chen, et al. A Fractional Total Variational CNN Approach for SAR Image Despeckling, accepted by ICIC2018 [PDF][CODE]
- Miao Chen, Yi-Fei Pu, Yu-Cai Bai, Low-Dose CT Image Denosing Using Residual Convolutional Network with Fractional TV Loss, accepted by Neurocomputing [PDF]
Experiences
Occupancy GT Generation based on Point Cloud
Occupancy, as a more general representation for robotic perception, is used in our perception task. In short, occupancy is a task with camera input only to inference the info for each voxel, including is_occupied, velocities, and semantics. However, the labelling for millions of voxel is expensive. In our work, we try to use a strong pseudo-labelling method to reduce the cost.

The labelling is divided into three parts. For the occupied status, multi frames in the scene is exploited and the points from all the scene is accumulated with motion compensation (ego and other moving objects). And, the semantics are obtained by lidarseg results. For the velocities, we focus on the methods based on SCENE FLOW, which could provide the flow for each point, and semi-supervised method (3D rigid) is our baseline model.
Auto Labelling (2022.1 - 2022.8)
In this project, we can use the off-board data to detect more accurately. The unlimited model size and whole video information are allowed to use. The metric is more serious than real-time detection, iou0.8 mAP and iou0.9 mAP.
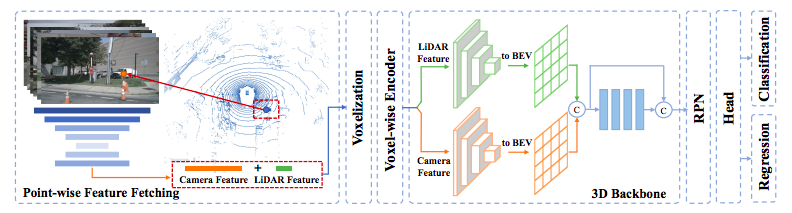
I am responsible for multi-modal (lidar+camera) detection and tracking. For the detection, we concatenate the extracted image feature with the point before convolution. Our experiment shows that the multi-modal model has dramatic improvement for the target with the sparse points. For the tracking, extra image information boosts the performance of the instance matching process, which helps us enlarge the matching range.
Advanced Driver Assistance Systems (ADAS) (2021.3 - 2021.12)
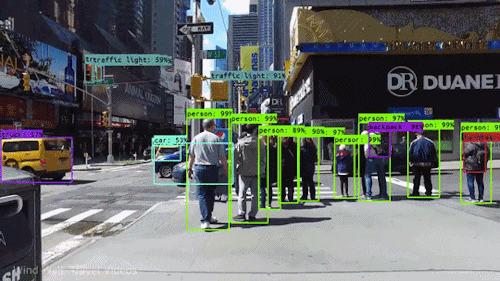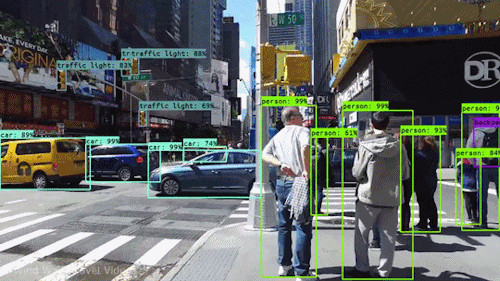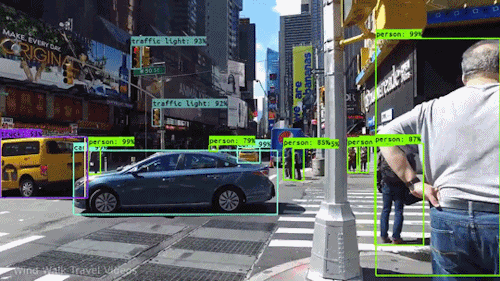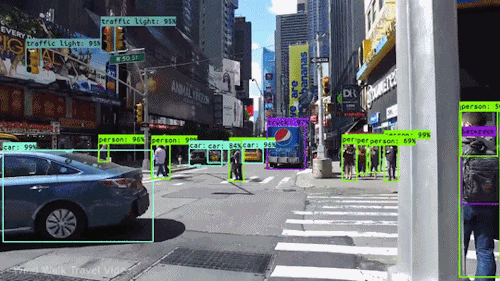
ADAS is an L2-level project of self-driving. Its perception part requires multi-class object detection based on forward-view images, including vehicles, pedestrians, traffic signs, obstacles.
I am responsible for:
- the optimization of specific categories.
- the improvement of training speed
- reducing communication time between machines
- framework (MMDetction) optimization
- the improvement of representation ability (with the assistance of the related task, e.g. semantic segmentation).
Local Automated Parking Assist (LAPA) (2020.9-2021.2)
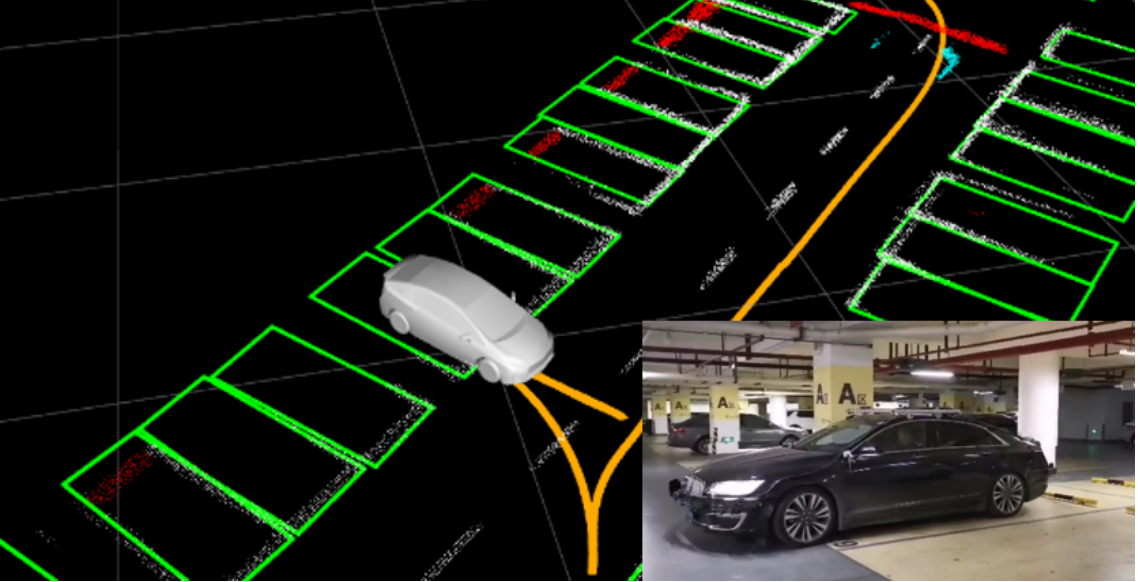
LAPA is an L4-level project to help driver park their vehicle more conveniently. To be specific, the car with LAPA could park itself in the selected/saved parking slot. The perception part is divided into two stages. The first stage is to map and save key information by SLAM system, such as trajectory and key objects. The second stage is to locate, including selecting the saved parking slot and constantly providing distance.
I am responsible for parking slot detection on the bird-eye images and the development of related functions (parking slot selection and related post processing). The difficulties involved are: strong light reflection on ground, the missing of key visual features, the fluctuation of detection results.
I also filed a patent for better detection in the environment with uncompleted visual features, which is in the review.
Extreme Low Resolution Action Recognition (2019.5 - 2021.2)
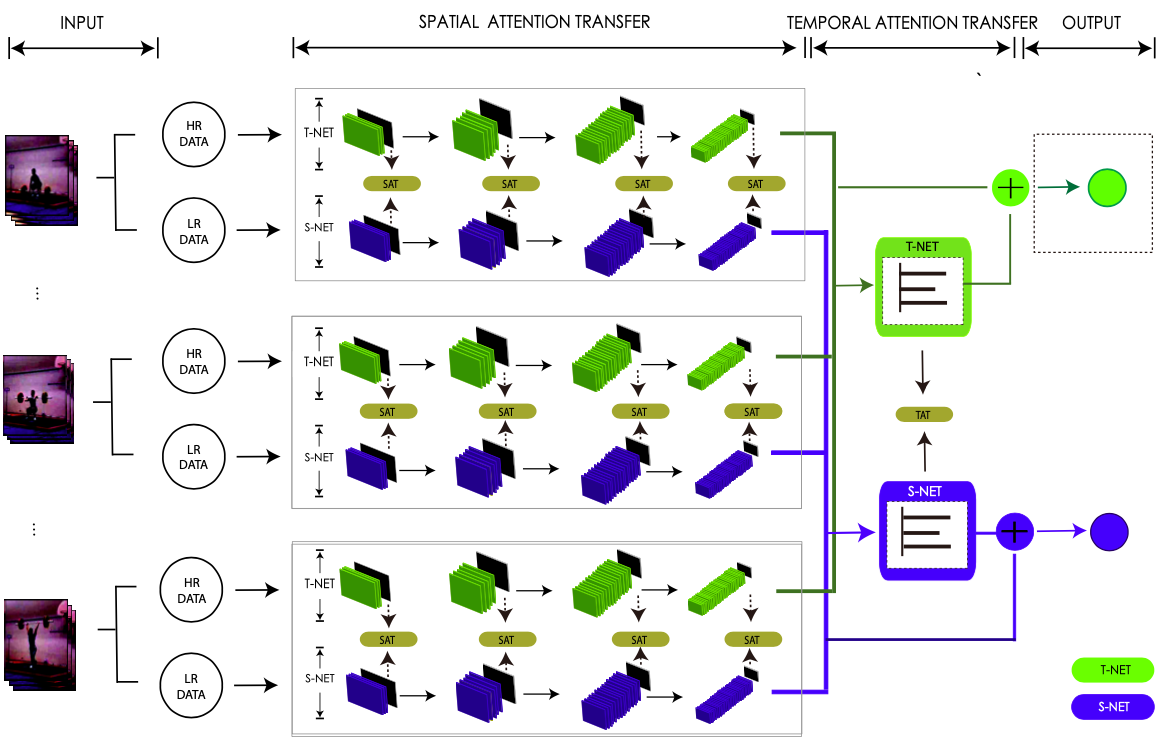
In order to solve the problem – people in the corners is very small and just contains limited pixels, we proposed a new method to recognize extremely low-resolution activities. which is based on Confident Spatial-Temporal Attention Transfer (CSTAT).
CSTAT can acquire information from high resolution data by reducing the attention differences with a transfer-learning strategy. Besides, the credibility of the supervisory signal is also taken into consideration for a more confident transferring process. Experimental results on two well-known datasets, i.e., UCF101 and HMDB51, demonstrate that, the proposed method can effectively improve the accuracy of eLR activity recognition, and achieves an accuracy of 59.23% on 12×16 videos in HMDB51, a state-of-the-art performance.
The corresponding paper is accpted by IJCV.
Non-compliance Action Detection of Court Scene in Surveillance Videos (2019.3 - 2020.6)
As the team leader, I took charge of the entire project, including the design and development of a real-time detection algorithm of the non-compliance actions and the production of the non-compliance action datasets.
The detection is divided into two stages. Firstly, we used the object detection algorithm to detect people and crop the corresponding area.
Then we used image-based algorithms to cope with the easy-to-classify categories and 3D convolution network techniques for more complex actions.
We won 2nd in the action recognition track of Teda·Huabo cup innovation and entrepreneurship challenge

3D Semantic Reconstruction from a Monocular Camera with a Novel Multi-task Network (2018.8 - 2019.2)
This work was performed when I visited Institute of Unmanned Systems @SYSU as a summer research intern, under the supervision of Prof.Chen.
We explored the interplay between low-level features for both depth and semantic prediction. The proposed network can produce the depth and semantic maps simultaneously, which provides basic knowledge for further semantic map reconstruction. We apply image segmentation techniques to refine the depth prediction to reduce the fluctuations caused by convolution layers. The final map is saved in a memory-friendly way to present a large-scale urban scene.
The corresponding paper is accepted by IROS 2019.
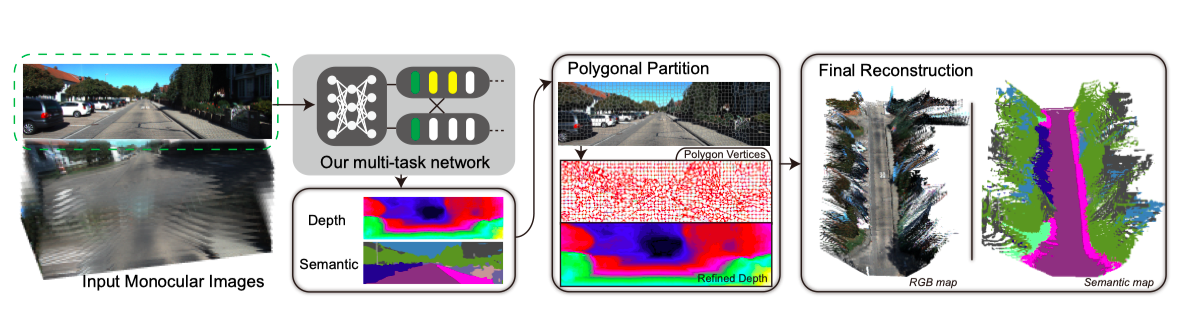
Image Despeckling with Fractional Total Variational Loss (2017.11 - 2018.5)
Motivated by the Applications in Fractional Calculus Course, we applied fractional-calculus techniques in the image denoising task. Due to its advantages, long-term memory, non-locality and weak singularity, the fractional-differential result of images can preserve the low-frequency feature in the smooth area such as contours, and at the same time, keep high-frequency information such as textures.
We proposed FID-CNN, a 8-layer CNN network with fractional total variational loss. Ablation experiments shows the proposed method has a better performance in preserving details .
The paper is accepted by ICIC2018.
We also transferred the main ideas to low-dose CT images and modified our method to make it more suitable for its characteristics. The paper is accepted by Neurocomputing.

ZBJ.COM Inc. Front-End Engineer Intern (2015.9 - 2016.2)
Worked in Basic Technology Department.
- Developed web sites Bajie Account, Bajie City pages
- Updated image format (jpg/png -> webp).
Honors
- Second Prize Merit-based Scholarship, SCU 2019.7
- Second Prize, 6th Teda · Huabo Cup, Action Recognition Track, 2019.6
- Excellent Postgraduate Student, SCU 2018.9
- Excellent Graduation Thesis, CQUPT 2017.6
- Third Prize Merit-based Scholarship, CQUPT 2015.9
Technical Strengths
Deep learning framework: Pytorch (MMDetection, det3d) > Tensorflow > Caffe
Coding language: Python, C++, JavaScript
English Language Level
IELTS: 6.5 (working on it !!!)
CET6